
DeepSeek V4第一天就能跑!本地Token生产平台来了
DeepSeek V4第一天就能跑!本地Token生产平台来了“AI新物种”企业级Token生产平台TokenBox™。
来自主题: AI资讯
5928 点击 2026-06-03 09:27
 搜索
搜索
“AI新物种”企业级Token生产平台TokenBox™。

DeepSeek V4发布,比模型本身更受关注的,是一个根本性的转变: 国产算力生态正在从过去“芯片被动适配模型”的单向奔赴,迈向“芯模协同”的新阶段。

超越 GPT-5.5、Gemini 3.5 Flash、DeepSeek V4 Pro,阿里的最新旗舰模型 Qwen3.7 Max 在编程竞技榜拿下第二名,仅次于 Claude Opus 4.7。除了真实场景的用户选择,在传统的大模型固定评测榜单上,像是终端能力 Terminal Bench、编程能力 SWE Bench 等,Qwen3.7 Max 的表现也是拿下了国产模型的冠军。

最近,DeepSeek又刷屏了!

4个月烧光全年AI预算,天价Token账单正在屠杀硅谷!今天,高性能Agent模型SkyClaw-v1.0出世,性能直逼Opus 4.6、DeepSeek V4 Pro,百万上下文性价比拉满。
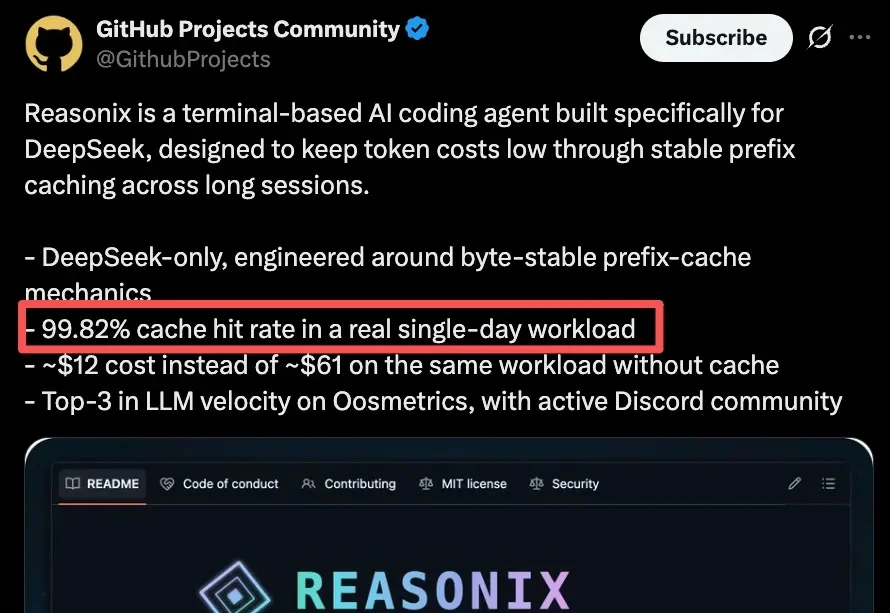
我悟了,DeepSeek V4系列发布1个月,价格屠夫的本色这才刚刚发力啊!

说实话,我原本以为 DeepSeek 的限时优惠会在5月31日结束。毕竟降价75%,打了2.5折,怎么看都像是一波限时引流。5月22号晚上,DeepSeek发了个通知,我看了两遍才确认没看错——DeepSeek V4-Pro永久降价!
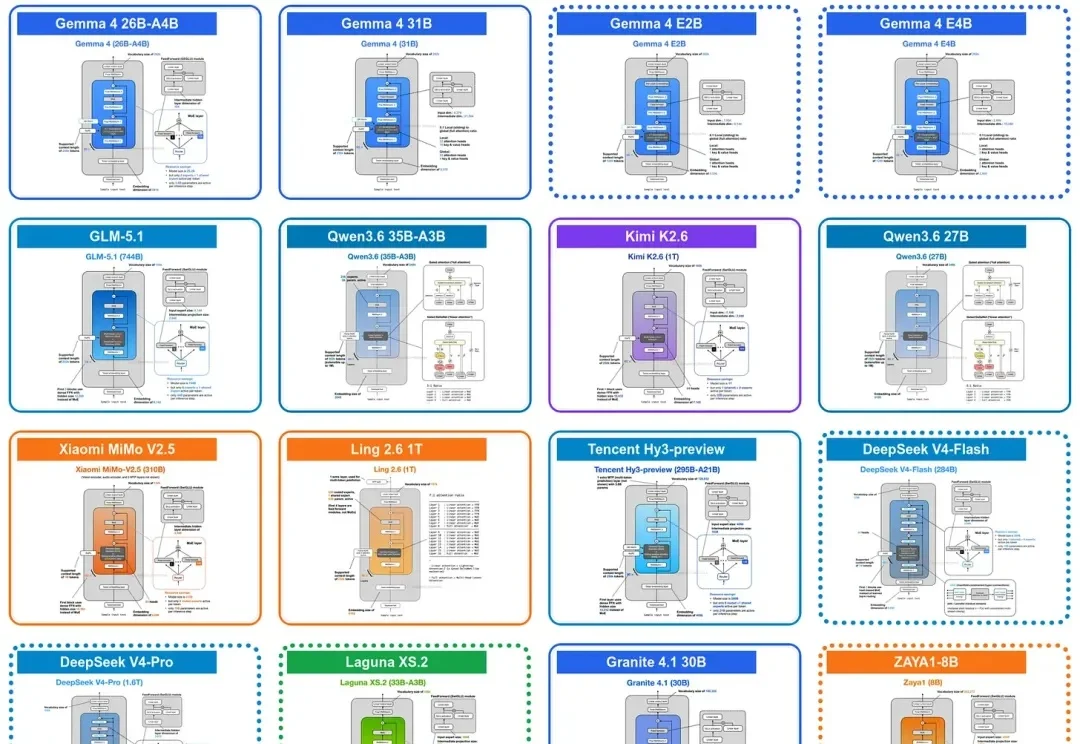
过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。
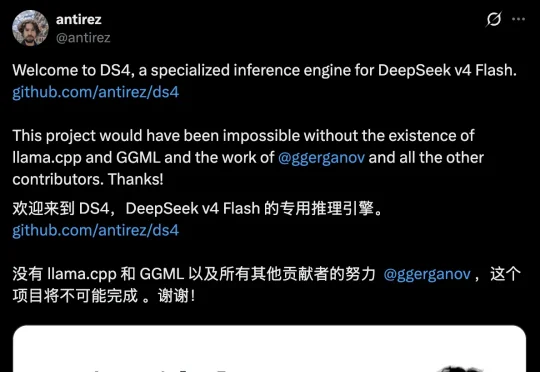
DeepSeek V4,已经开始逼着海外开发者为它修专属高速公路了。发布才两周,开源圈里,第一批V4原生基础设施已经冒了出来。它只干一件事:把DeepSeek V4 Flash,在Mac上跑到极致。这条“专属高速公路”,叫ds4.c。而把修出来的人,分量有点吓人——
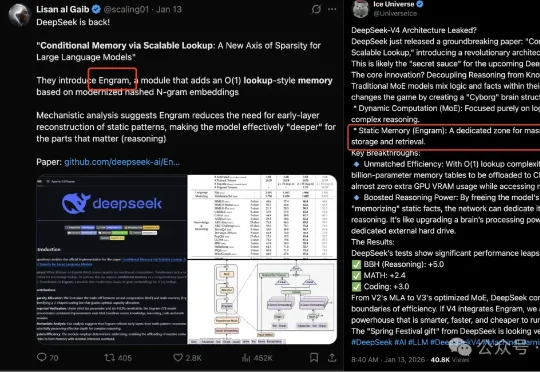
DeepSeekV4的技术报告里有mHC,有CSA,有HCA,有Muon,有FP4……唯独没有Engram。Engram在今年1月由DeepSeek和北大联合开源,主要研究大模型的记忆与效率问题。